Bezpieczeństwo czy wydajność? Jakie decyzje podejmą producenci procesorów?
Ostatni rok obfitował w informacje o wykryciu nowych luk związanych z architekturą procesorów. W większości przypadków są one trudne do usunięcia bez straty wydajności. Jak z tymi problemami chcą sobie poradzić najwięksi producenci układów scalonych?
Dnia 21 sierpnia tego roku zakończyła się trzydziesta edycja konferencji Hot Chips, na której czołowi producenci sprzętu, np. Intel, Nvidia, AMD i ARM, przedstawiali swoje nowe architektury i produkty. Jednym z głównych tematów były mechanizmy zapobiegania Spectre i Meltdown. Ataki kanałami bocznymi są znane i praktykowane od lat siedemdziesiątych. Istnieje jednak istotna różnica pomiędzy Spectre i Meltdown a wcześniejszymi zagrożeniami — w przeszłości celem większości tego typu ataków była warstwa aplikacji, czyli oprogramowanie. Teraz obiektem zainteresowania stała się platforma sprzętowa, na której kod jest wykonywany. Luki sprzętowe można łatać (przynajmniej częściowo) za pomocą oprogramowania, czego dowodzą najnowsze wyniki związane ze Spectre i Meltdown. Jest to jednak czasochłonne, kosztowne, a także odbywa się przy znaczącym spadku wydajności.

„Aby uniknąć luk, należy albo dodać dodatkowe zapytania do architektury procesora albo zapobiec spekulacyjnemu wykonywaniu kodu”, powiedział podczas konferencji John L.Hennessy, rektor (prezydent) Uniwersytetu Stanforda, znany autor książek z dziedziny architektury komputerów, jak i ojciec architektury RISC obecnie stosowanej w 99% nowych układów scalonych (za co w zeszłym roku otrzymał nagrodę Turinga). Obie metody mają wady. Zmiana mechanizmów sprzętowych wymaga wymiany sprzętu w całej organizacji. Jest to drogie, a często wiąże ze sobą problemy z kompatybilnością wsteczną i samym transferem danych, jak również nie wyklucza spadku wydajności o 15–20 procent. Wyłączenie spekulacyjnego wykonania kodu wiąże się ze zdecydowanym spadkiem wydajności w wielu aplikacjach, często o ponad 30 procent. Ten spadek jest nie do zaakceptowania dla większości użytkowników.
Czy nie ma zatem żadnych pozytywnych wiadomości? Na szczęście są. Po pierwsze, wyciek danych w atakach przeprowadzony za pomocą tych luk jest w większości scenariuszy czasochłonny. Na przykład NetSpectre, atak zdalny bazujący na podatności Spectre, prowadzi do wycieku danych z serwerów ze średnią prędkością ok. 1 bitu na minutę (wartość zależy od konkretnej realizacji). Z drugiej strony, średni czas pomiędzy penetracją serwera a wykryciem włamania wynosi obecnie 100 dni. Wyniki są efektem najnowszych badań Johna Hennessego.
Po drugie, wyniki Google Project Zero przedstawione przez Paula Turnera uspokajają i wskazują na to, że siła ataku była znacznie przeceniona – szczególnie bezpośrednio po prezentacji luk dla szerszej publiczności. Przez ostatnie miesiące wszystkie opublikowane modele wykorzystania luk ograniczają się do wycieku danych z pamięci. Ataki, które manipulują danymi w pamięci albo wprowadzają złośliwy kod do wykonania, pozostają wciąż w sferze teorii i spekulacji. Miejmy nadzieję, że tak pozostanie.
Niestety przez ostatnie osiem miesięcy okazało się również, że przy opisie możliwych konsekwencji ataku opierano się często na fałszywych przesłankach. Zakładano, że spekulacyjne wykonywanie kodu nie pozostawia śladów, gdy prognoza jest błędna, ponieważ wyniki zostają odrzucone. To ostatnie twierdzenie jest prawdziwe tylko dla logiki programu – nie występują błędy obliczeniowe. Stany w procesorze są jednak inne niż w przypadku prawidłowej prognozy. Ponadto, dzięki stale zwiększającej się pojemności pamięci głównych, dane są często posortowane i bezpośrednio adresowalne – atakujący nie musi już pracować z oknami i zakresami obszarów pamięci. Oba czynniki znacznie ułatwiają przeprowadzanie ataków.
Zmiany paradygmatów w przyszłych architekturach sprzętowych
Dotychczas przedstawione rozwiązania dla problemów związanych z Spectre i Meltdown jednoznacznie wskazują na to, że dotychczasowe podejście – ścisły podział zadań pomiędzy sprzęt i oprogramowanie – staje się obecnie głównym źródłem problemów. Jak stwierdził Jon Masters z firmy Red Hat, myślenie w kategoriach „my” i „oni” w stosunku do twórców sprzętu i oprogramowania wydaje się w dłuższej perspektywie nie do utrzymania. Jest to związane z poziomem abstrakcji wpływającym na jakość mechanizmów bezpieczeństwa. Prawie cała poprawa wydajności współczesnego procesora wynika z agresywnych metod optymalizacji, takich jak wykonywanie poza kolejnością (ang. out-of-order execution) czy spekulacyjne wykonywanie kodu. Mimo że warstwa aplikacyjna ma wprowadzone mechanizmy bezpieczeństwa (np. prawa dostępu, kolejność wykonania), sprzęt je w dużej mierze ignoruje w procesie optymalizacji wykonania kodu. Prowadzi to do niwelowania działania programowych mechanizmów bezpieczeństwa i pojawiania się kolejnych luk. Ponadto agresywna optymalizacja jest trudna do kontroli dla programistów. Jest ona bowiem zaprzeczeniem sekwencyjnego przetwarzania kodu implementowanym przez większość kompilatorów kodów i modeli programowych. W rezultacie programiści języków wysokopoziomowych są często nieświadomi ograniczeń i właściwości platformy sprzętowej, na której pracują i tracą kontrolę nad wykonywanym kodem maszynowym. Jak wyjaśnił Mark Hill z Uniwersytetu Wisconsin, oddzielenie sprzętu i oprogramowania zapewniało w przeszłości praktyczną budowę modularną systemu zorientowaną wokół modelu programowego procesora ISA (od ang. instruction set architecture) z jasno określonym podziałem ról. Aplikacje były tworzone dla konkretnego zestawu instrukcji, a twórcy procesorów dbali o jak najszybsze wykonanie tych instrukcji. Jednak rozwiązanie wyżej wymienionych problemów prowadzi do nowej architektury, w której sprzęt i oprogramowanie ponownie zbliżają się do siebie.
Jedną z popularnych koncepcji dla przyszłych architektur sprzętowych są dodatkowe tryby pracy procesora, np. rozróżnienie trybu szybkiego i bezpiecznego. W tym drugim przypadku, procesor używa buforowania i wykonania spekulacyjnego tylko w ograniczonym zakresie. Alternatywą jest wykorzystanie multi-procesorowych architektur heterogenicznych, w tym łączenie różnych rdzeni o różnych charakterystykach bezpieczeństwa. Na Hot Chips dyskutowano również o nowych modelach biznesowych, np. maszyny wirtualne na bezpiecznych, ale wolnych serwerach za dodatkową opłatą. Na koniec warto zauważyć, że przejście do otwartych architektur typu open source może wydarzyć się również dla sprzętu (nowe koncepcje bezpieczeństwa na procesorach RISC-V), przynosząc konkretną poprawę mechanizmów bezpieczeństwa – tak jak dzieje się to w przypadku oprogramowania.
Konkretne rozwiązania?
Jak dyskusje projektantów i badaczy przekładają się na konkretne wdrożenia? Jako jeden z nielicznych, Intel w swojej prezentacji na konferencji przedstawił konkretne rozwiązania i mechanizmy. Trzeba jednak dodać, że miejsce i czas nie są przypadkowe. Wygląda na to, że prace nad obiecanymi na koniec 2018 roku architekturami odpornymi na ataki „spekulacyjne” prowadzone są bardzo intensywnie – chociaż nie można wykluczyć opóźnień. Pierwszą serią zawierającą tego typu rozwiązania powinna być rodzina procesorów Cascade Lake SP do implementacji serwerowych. Spekuluje się również o wprowadzeniu mechanizmów bezpieczeństwa do ośmiordzeniowego i-9000 (LGA1151v2) oraz chipów z rodziny „Whiskey-Lake” przeznaczonych do notebooków i laptopów.
| Nazwa techniczna | Nazwa zwyczajowa | Umiejscowienie mechanizmu bezpieczeństwa dla platformy Cascade Lake |
|---|---|---|
| Spectre V1 | Bounds Check Bypass | System operacyjny / hypervisor |
| Spectre V2 | Branch Target Injection (BTI) | Mechanizm sprzętowy + system operacyjny / hypervisor |
| Meltdown (V3) | Rogue Data Cache Load | Mechanizm sprzętowy |
| Spectre V3a | Rogue System Register Read | Sterowniki |
| Spectre V4 | Speculative Store Bypass | Sterowniki + system operacyjny / hypervisor albo oprogramowanie |
| Spectre-NG | L1 Terminal Faul (L1TF) | Mechanizm sprzętowy |
Rysunek 1. Umiejscowienie nowych mechanizmów bezpieczeństwa dla platformy Cascade Lake
W tabeli przedstawiono zestawienie mechanizmów, klasyfikując je na podstawie luki i wdrożenia (oprogramowanie, sprzęt lub oba). Mechanizmy wykonane w pełni sprzętowo zabezpieczają tylko przed Meltdown i niedawno wykrytym błędem L1 Terminal Fault (L1TF). W przypadku Spectre V2 (BTI) funkcje sprzętowe muszą współpracować z odpowiednimi łatkami systemu operacyjnego lub wirtualizacji oprogramowania nadzorcy (ang. hypervisor). Sprzętowych mechanizmów ochronnych nie przewidziano dla Spectre V1. W pozostałych przypadkach poprawki sterowników będą konieczne. Warto zauważyć też, że tylko jedną lukę z sześciu (Spectre V1) można usunąć w pełni programowo bez modyfikacji mechanizmów sprzętowych.
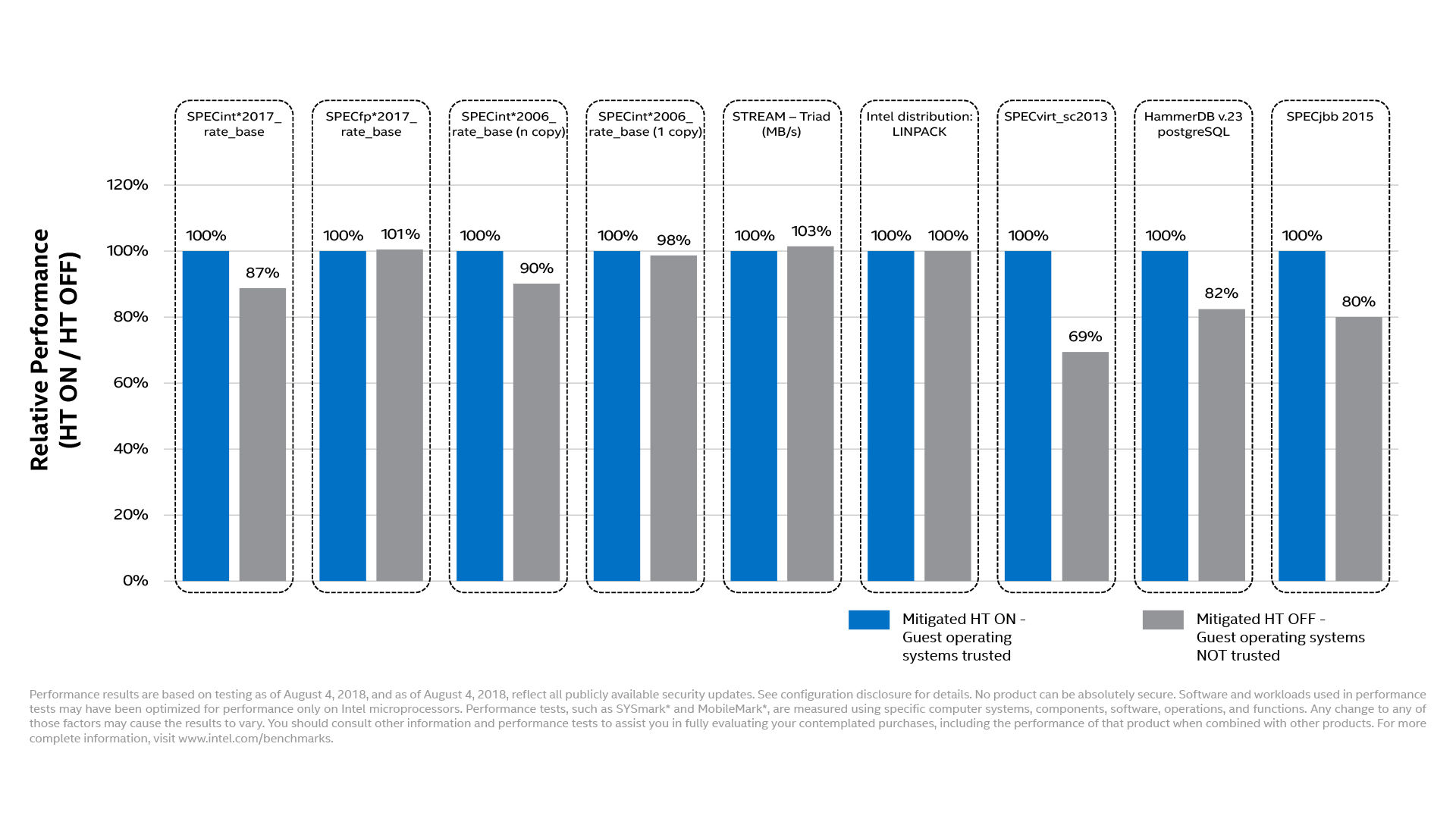
Rysunek 2. Spadki wydajności związane z nowymi mechanizmami bezpieczeństwa zaprezentowane przez firmę Intel, źródło: Intel
Wygląda też na to, że nie obędzie się bez spadków wydajności. Przedstawione wyniki – patrz Rysunek 2 – potwierdzają, że wyłączenie Hyper-Threadingu wymagane do zabezpieczenia przed L1TF znacząco zmniejsza wydajność procesorów Xeon w wielu aplikacjach (co było do przewidzenia). Spadki wydajności są największe w przypadku serwerów z wieloma maszynami wirtualnymi (ataków z użyciem złośliwych wirtualnych maszyn). Sprzętowe mechanizmy ochronne w większości wypadków zapewniają jednak zdecydowanie lepszą wydajność niż wcześniejsze poprawki, np. poprzez aktualizacje mikrokodów, udostępniane od początku roku.
Podsumowanie
Droga do rozwiązania problemów Spectre i Meltdown wydaje się długa, a cały proces kosztowny. Bez głębokich zmian w architekturze, wpływających na całe procesy produkcyjne, trzeba się liczyć ze stratami wydajności. Straty te są jednak w większości wypadków nie do zaakceptowania dla wielu obecnych klientów, np. dostawców usług internetowych. W związku z brakiem konkretnych rozwiązań dyskusje zaczynają być nie na rękę tak dla producentów sprzętu (drogie i ryzykowne inwestycje w nowe mechanizmy i rozwiązania), jak i oprogramowania (trzeba tłumaczyć klientom, dlaczego wirtualne maszyny nie spełniają wszystkich norm bezpieczeństwa bądź z dnia na dzień podnosić ceny). Dyskusje medialne stają się zatem bardziej wyważone i stonowane. Coraz rzadziej słyszy się żądania bezwarunkowej rezygnacji ze spekulacyjnego wykonywania kodu na maszynach serwerowych – czego żądano w styczniu tego roku.
Artykuł opiera się na źródłach prasowych heise.de, eetimes, jak również na oficjalnych źródłach organizatorów konferencji. Na stronie konferencji można także znaleźć nagrania wideo z jej najciekawszych dyskusji.
Artykuł był opublikowany również w serwisie ZaufanaTrzeciaStrona.